バックエンドエンジニアインターン生の倉永です。インターン期間中、DynamoDBへAuto Scalingを導入するか検討した際に、色々と気づきが多かったので、それについてお話しします。
背景
NatureではNature Remo Eという商品を販売しています。Nature Remo Eを使うと、家庭で消費した電力のグラフを以下のようにアプリで確認できるようになります。

このテーブルは以前、プロビジョンドキャパシティモード(当時はAuto Scalingなし)で運用されていたのですが、これがサーバ障害の原因となってしまいました。別の障害に起因してテーブルへの書き込み負荷が増加し、スロットリングによる遅延が発生することでデータを書き込むサーバの負荷も増加してしまったことが原因です。
現在はオンデマンドキャパシティモードで運用していますが、料金が高いという課題があります。そこで、 オンデマンドキャパシティモードの代わりに、プロビジョンドキャパシティモードとAuto Scalingを導入することによって、料金を削減しつつ、過去の障害と同じような書き込み負荷の増加に対処できるのかを検討したのが今回の趣旨です。なお、DynamoDBの読み込み処理については本記事では言及しません。
要件
もしプロビジョンドキャパシティモードとAuto Scalingで運用していくのであれば、障害時と同等の負荷が発生しても「データをロストせずにスロットリング状態から復旧」して欲しいです。これを要件として進めていくことにしました。
Natureの電力データの書き込みにはguregu/dynamoというOSSが使用されており、書き込みリクエストに失敗した際はエクスポネンシャルバックオフアルゴリズムにより最大15分間リトライをするよう設定してあります。 つまり、スロットリングが発生し始めてから15分以内に復旧できれば要件が満たせるわけです。 なお、リトライの持続時間を伸ばすという対応は今回考えないこととします。
調査と分析
当該の障害ではテーブルにどれくらいの書き込み負荷がかかっていたのか知りたかったので、「1秒あたりの書き込みリクエスト数」に焦点を当てて調査と分析を行いました。調査の結果、一度に書き込まれる電力データの容量はすべて1KB以下であったので1、
1秒あたりの書き込みリクエスト数(req/sec) = 1秒あたりに消費されたWCU(wcu/sec) + 1秒あたりの書き込みスロットリング数(throttling/sec)
と考えました。また、当時発生したスロットリングはすべて書き込みによるものだということもわかったので、「1秒あたりの書き込みリクエスト数」はDynamoDBのメトリクスであるConsumedWriteCapacityUnits2とThrottledRequests3から算出できると考えました。
以下は、障害発生直後のConsumedWriteCapacityUnits、ThrottledRequestsメトリクスのグラフ(DataDog)です。
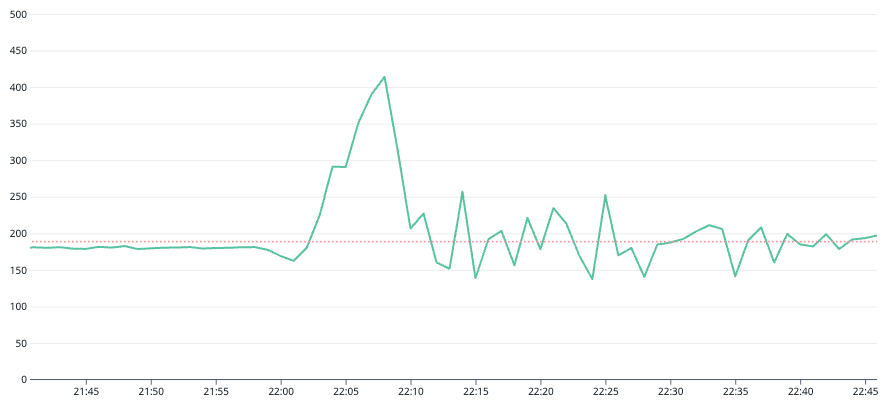

通常時の消費キャパシティユニットは190wcuあたりで安定しているのですが、22時を過ぎたあたりからグラフに大きな変化があるのがわかると思います。 ThrottledRequestsは、書き込み負荷が増加し始めてから数分で150k(throttling/min)に到達しました。このときのConsumedWriteCapacityUnitsは160(wcu/sec)でした。150000(throttling/min) = 2500(throttling/sec)なので、
160(wcu/sec) + 2500(throttling/sec) = 2660(req/sec)
相当の書き込みリクエストがあったと考えられるでしょう。その当時にどれだけの書き込みリクエストがあったのかを算出する際には、消費キャパシティユニットだけではなくスロットリング数も考慮しないといけないというのは良い気づきでした。 また、グラフ上にはありませんが、別の時間帯で最大3800(req/sec)相当の書き込みリクエストがあったことも確認しました。
以上の調査と分析から、短時間の間に通常時の約10~20倍もの急激な負荷増加が発生し、それが長時間続いていたことがわかりました。
検証
実際に障害時と同じような負荷をシミュレートして、Auto Scalingがその負荷に対処できるのか検証していきます。以下はシミュレートする際に使用するテーブル設定の一部です。
| 項目 | 値 | 補足 |
|---|---|---|
| Target Value | 90% | 通常時の消費キャパシティユニットは常に一定 |
| Min Capacity | 211wcu | 190wcuに対し、TargetValueが90%だと閾値が約211wcuとなる。Min Capacityを211に設定しておき、190(req/sec)の負荷を5分(300秒)間かけることで、障害当時のバーストキャパシティ4の残量を再現したい |
| Warm Throughput | 4000wcu | >= 3800wcu(瞬間最大風速) |
検証を簡単にするため、190wcuを消費していたところ、いきなり瞬間最大風速値である3800(req/sec)の負荷がかかり始めるという状況を想定してみます。15分以内に3800wcuを消費できるまでスケールアウトをすることが確認できれば今後同じような障害が起こっても問題ないでしょう。
DynamoDBのテーブルに負荷をかけるにあたって、YCSB(Yahoo! Cloud Serving Benchmark)というツールを使用しました。 使い方については、下記の記事がとても参考になります。aws.amazon.com
負荷テストの結果です。

結果として、負荷をかけ始めて15分時点では約1500wcuを消費できるようになっていることを確認しました。障害発生時の負荷が約2000~4000(req/sec)だったことを考えると、もう少し余裕を持ってスケールアウトしてほしいです。Target Valueの値を低めに設定しておけばバーストキャパシティをより多く確保できるので、スケールアウトはもっと早いのでしょうが、それだと目的である料金削減を達成できません。
Auto Scalingで今回のような負荷増加に対処するのは難しそうだと感じたので、今後同じような負荷増加が起きた場合は、手動でオンデマンドキャパシティモードに変更をするというオペレーションにしておくことにしました。オンデマンドキャパシティモードであれば即座に4000(wcu/sec)を消費できる6ため、今回の要件は満たせるはずです。 少々雑な対応な気がしますが、数年に1回あるかないかの負荷を想定しているので、これ以上手の込んだ仕組みを整える必要はないという判断です。これで安心してテーブルをプロビジョンドキャパシティモードへ移行できます。 ただ、Auto Scalingは導入しておいて損はないので、導入はすることで決定しました。
今回は急激なバーストが長時間続く際にどのようにスケールアウトをするのか検証しましたが、徐々にスループットが上昇するような場合についてはこちらの記事がとても参考になります。 Amazon DynamoDB のプロビジョンドキャパシティを使用した突発的なトラフィック増加への対処 | Amazon Web Services ブログ
Auto Scalingの導入
Natureの電力データ周りのインフラは月次で管理をしています。毎月手動でインフラを構築するわけではなく、Goで書いたCLIコマンドをScheduled Tasks(ECS)で動かすことによって自動化しています。月次で作成されるDynamoDBテーブルにAuto Scalingが適用されるようにしたかったので、今回はそのためのCLIコマンドを作りました。
作成したCLIコマンドでは、いくつかのAPIリクエストを行うことで最終的にリソースが目的の状態になるのですが、途中でリクエストが失敗すると、リソースが不完全な状態になってしまうという課題がありました。これでは障害の原因になりかねないので、
を行うことにしました。 また、APIリクエストが中途半端に失敗した際、手動でリソースを直していくのは大変だということで、アドバイスをいただき、このCLIコマンドに冪等性を持たせることにしました。こうすることで、コマンドをリトライするだけでリソースを目的の状態に変更できます。
以前は冪等性について「なんとなく理解している」程度でしたが、今回自分で実装することで理解が深まり、とても勉強になったと感じています。
まとめ
今回はDynamoDBの料金を削減するために、DynamoDBへAuto Scalingを導入するか検討していきました。結果として、今回のような負荷増加が起こる状況では、Auto Scalingでの対処が難しいことがわかりました。保険としてAuto Scalingの導入は行いましたが、急激な負荷増加が起こった際には手動でオンデマンドキャパシティモードに変更することにしました。
蛇足
2024年11月に新しく発表されたwarm throughputの特徴について気づきがあったので共有させてください。
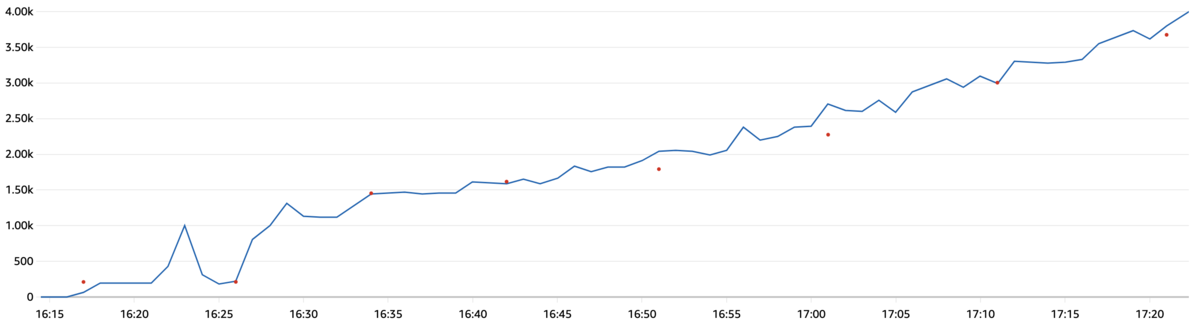
今回のように常にスロットリングが発生するような負荷がテーブルにかかる場合、pre-warmingをしてもあまり意味がありませんでした。
以下がpre-warmingなしで検証時と同じ負荷をかけた時のConsumedWriteCapacityUnitsメトリクスのグラフです。
検証(pre-warmingあり)の時とスケールアウトのスピードにさほど変化がないことがわかると思います。
インターンの感想&すゝめ
夏からNatureにジョインして、早くも半年が経とうとしています。この間、API開発からCI/CD、インフラ、OSS活動などと様々なことを経験させてもらいました。最近は積極的にコードレビューに参加するようにしており、経験豊かなエンジニアの書いたコードを読みまくることでモリモリと力がついている気がします。他のインターン生が書いたブログをご覧いただければわかると思いますが、Natureではインターン生であっても、裁量権を持ってタスクに取り組むことができます。今回の「DynamoDBへAuto Scalingを導入するか検討する」タスクにおいても、チームの方にたくさんのアドバイスはいただきましたが、基本的には自分の判断で進めていきました。もちろんそれだけの責任感と技術のキャッチアップが求められますが、インターンをするにはとても刺激的な職場だと思います!
私の感想がこれからNatureでインターンを考えている方々の参考になれば幸いです!
- DynamoDB の読み込みと書き込みのオペレーション - Amazon DynamoDB↩
- DynamoDB のメトリクスとディメンション - Amazon DynamoDB↩
- DynamoDB のメトリクスとディメンション - Amazon DynamoDB↩
- DynamoDB バーストキャパシティとアダプティブキャパシティ - Amazon DynamoDB↩
- Amazon DynamoDB のプロビジョンドキャパシティを使用した突発的なトラフィック増加への対処 | Amazon Web Services ブログ↩
- DynamoDB オンデマンドキャパシティモード - Amazon DynamoDB↩