こんにちは大塚(@maaash)です。7月からCTOに復帰しました。引き続きよろしくお願いいたします。 これは第2回 Nature Engineering Blog 祭11日目のエントリです。

昨日はファームウェア・エンジニアの村田さんによる Matterでやりたかったけどできなかったこと - Nature Engineering Blog でした。
今日のお話は、話題の新製品Remo nanoやMatterとは関係ありません。
背景
先週、黒田さんが ウン十万接続のALB SSL証明書を平和に更新したい - Nature Engineering Blog を書いてくれました。 その話は
ALBを二台用意して緩やかに接続を移行するようにしたら、大変平和になって僕もみんなもハッピーになった。
という話でした。ALB blue-green deploymentを使うと、ウン十万のRemoたちが24-36時間くらいかけて緩やかに新しいALBの方につなぎに来てくれます。
今日は、ALBの後ろにいるECSサービス(先の記事でstreamサーバと呼ばれていたやつです)をデプロイしたい話です。
ALBは3ノードの話だったので、(blue-green deploymentを使わない場合) ウン十万接続の1/3が短期間のうちにバッサリ切られて一気に再接続してきました。
streamサーバも多くはありません。 今は8台のstreamサーバがいるので、ウン十万接続の1/8を一度に切断して、再接続してもらいます。1/3ほどではありませんが、1/8でも相当です。
あれ?でも(Websocketでない)普通のHTTP APIサーバではそんなことありませんよね。NatureでもAPIサーバは一日に何度もデプロイしていてそのたびに一度に切断なんて気にしていません。なんでだっけ?
APIサーバの停止
ECSはサービスのデプロイ時、旧タスクを1つずつ停止しながら、auto scalingやdesired taskの設定を満たすように新タスクを起動していきます。 ALB+ECSの構成では、以下のようにタスクの停止が行われます。

Graceful shutdowns with ECS | Containers より
ざっくりと以下のような流れです。
1 ECSがタスクをALBのターゲットグループから外す
2 ALBのターゲットはdraining状態になり、新規のリクエストはこのターゲットには転送されなくなる
3 deregistration delayが経過する
4 ECSがタスクのコンテナにSIGTERMを送る
5 その後stop timeoutが経過するとSIGKILLを送る
APIサーバは1リクエストにレスポンスを返すのに長くても数秒〜10秒で返すので、それよりderegistration delayやstop timeoutが長ければ特に問題にはなりません。
1~3の間はコンテナの中のGoプロセスに知らせる方法は(基本的には)ないので、4.から「SIGTERMが来たらgraceful shutdown」することになります。
Graceful shutdownといっても、Go言語を使っていればただ http.Server.Shutdown を呼ぶだけです。
何もしなくても、時間が経てば接続中のリクエストには長くても10秒以内にレスポンスが返り、全部のレスポンスが返ったらShutdownから制御が戻ってきます。
deferで後片付けをして死ぬ。お行儀よいです。
APIサーバでは、3のderegistration delayをレスポンスを返すlatencyに合わせて(この例では)10秒程度に設定しておけば、
4でSIGTERMを受ける時点ではレスポンスを返し終わっています。その場合http.Server.Shutdownは一瞬で完了し、stop timeoutに対して余裕をもって終了できます。
streamサーバの停止
streamの場合は、1リクエストにつき24~36時間の間、websocket接続を保持しているので、もう少し工夫が必要なことはわかっていました。
でもそんなに難しいってことはないですよね、 stop timeoutを長めにして、「SIGTERMを受けたらstop timeoutの間に、今持っているwebsocket接続を少しずつ切断すればよいだろう」 と思っていました。
Task definition parameters - Amazon Elastic Container Service によればstopTimeoutは最長120秒なので、 たとえ10万接続持っていても、120秒の間に少しずつ切断すれば、切断されたRemoたちがつなぎなおしに来ても 1000req/sec くらいです。それくらいなら大丈夫でしょう。ね。
楽しい日々
func (c *Stream) eventLoop(ctx context.Context, ...省略) { disconnect := make(chan struct{}) go func() { select { // SIGTERMが来たのでランダムな時間経過後に切断する case <-c.shuttingDown: closeAfter := time.Duration(rand.Int63n(int64(GracefulShutdownPeriod))) _ = time.AfterFunc(closeAfter, func() { close(disconnect) }) case <-ctx.Done(): return } }() for { select { case <-ctx.Done(): // 普通に切断 return nil case <-disconnect: // graceful shutdown中に切断 return nil case <-msg: // メッセージをwebsocketに流す // 省略 } } }
こういうchan, selectを使いまくるコード楽しいですよね。Go書いてる!わいわいエンジニア陣からprにコメントがついて、 GracefulShutdownPeriodをチューニングするだろうな、と環境変数から設定できるようにして、 signalやクライアント側も含めたテストも大変だけど書いて...
悲嘆
これをデプロイしてもうまくいかない。SIGTERMを受けてからなぜか8秒で全接続が切断される..!
signalからcloseスパイクまで8秒しか経ってないな。8秒ってなんだ。 ... が、実際にはランダムスリープ後の切断 (= ws:disconnect) ではなく、 srv.Shutdownの8秒後くらいにいっきにws:closedで終わっているという。
この頃は自身のバグを主に疑っていたのですが
なんでclosedになるかは自分も今のところわかっていなくて、なんとなくstreamの外で切られているんじゃないかなあと思っています。 なぜかというと、signalを受けた時の動作は stream/integration_test.go#L40 でシミュレーションしていて、streamに閉じている分には8秒で切れる、って現象は起きてないんですよね。。
websocket: close 1006 (abnormal closure): unexpected EOF error も大量にでている
このエラーから??となり似たような現象について言及しているGrammarlyのブログ Perfecting Smooth Rolling Updates in Amazon Elastic Container Service | Grammarly Engineering Blog を発見しAWSサポートに確認し判明したのは、 上の1~5のステップの4と5の間にALBが接続を切っているとのこと。
4 ECSがタスクのコンテナにSIGTERMを送る
4.1 ↑の後8秒程度でALBは既存の接続を切る
5 その後stop timeoutが経過するとSIGKILLを送る
このふるまい、ドキュメントに書いてないですよね?
stop timeoutの終わりまで接続は切らないと思いませんか。
- Graceful shutdowns with ECS | Containers には以下のようにあります...
Deregistering the task ensures that all new requests are are redirected to other tasks in the load balancer’s target group while existing connections to the task are allowed to continue until the DeregistrationDelay expires.
(ALBとECSが別のコンポーネントであることを考えると、ALBはstop timeoutのことは知らないし、deregistration delayタイマーを開始した後はECSからの入力がないのかな〜などと想像します)
解決
SIGTERMを受けてからでは間に合わないので、もっと手前でgraceful shutdownを開始する必要があります。 Grammarlyの記事やAWSサポートからの回答を得ていくつか解決方法は考えられます。
- Goの中で自分のECSタスクがどういう状態かをポーリングして状態変化を検知したらgraceful shutdownする
- Goの中で自分の(ターゲットグループの)ターゲットの状態をポーリングして〜
- ALB,ECSのイベントをLambdaで受けて〜
- ALBとECSの連携を切って自前で連携させる
などありましたがもろもろありbで行くことに。
つまり自身でDescribeTargetHealthWithContextを定期的に呼び、状態がdrainingになったら、
(長めに設定した)deregistration delay以下でマージンをとり設定した期間の間に少しずつwebsocket接続を切断していきます。
Before/After
これの導入により、streamサービスデプロイ時の新規接続のグラフは以下のようになりました。
Before
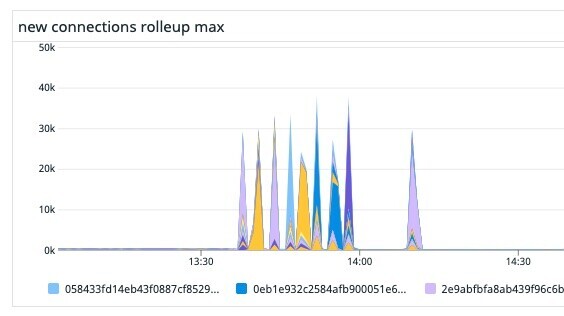
After

まとめ
Websocketなど長時間接続を保持するECSサービスを安心してデプロイするために、ターゲットグループの状態をポーリングしdrainingになったら自らgraceful shutdownするようにしました。
このようなマイナーな問題について書いてくれたGrammarlyのエンジニアには感謝しています。同様にこの記事が未来の誰かの役に立つことを願います。
宣伝
最後まで読んでくれてありがとうございます。 今日、この後 Nature Matter Kaigi - connpass ですよ! おもしろい話が聞けそうです。よろしければご参加ください。
お知らせ
Nature エンジニアコミュニティ
エンジニアコミュニティはじめました。Matter を使った Nature Remo nano の活用方法から Nature Remo could API の疑問など、Nature のエンジニアがお答えします! Discord への参加はこちらから。 https://discord.gg/3Ep57Muuuc
Nature Remo nano 好評発売中!
Matter 対応の Nature Remo nano が定価3,980円で発売中!
